

首先创建一个标签为本文网址,勾选后面的“从网址中采集”。
选择下面的“正则提取”,点击通配符“(?<content>?)”,这样在窗口中就显示为(?<content>[\s\S]*?) 我们再在它前加一个与字符串开始的地方匹配的符号^,又在它后面加一个与字符串结束的地方匹配的符号$,这样就变成了^(?<content>[\s\S]*?)$。
如图:
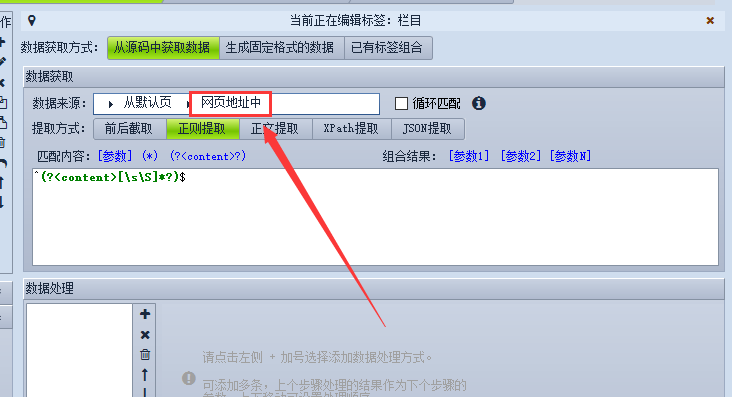
Content 代表内容
? 表示匹配0次或者1次
\s 匹配所有空白字符
\S 匹配所有非空白字符
* 修饰匹配次数为 0 次或任意次
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END




![表情[aoman]-红穆笔记](https://www.4s5.cn/wp-content/themes/zibll/img/smilies/aoman.gif)




暂无评论内容